

在线AI知识库信息检索能力测试(2025.10)
最近要读的文献很多,有一定比例是信息整理的活。所以打算综合测试主流的知识库 AI 搜索软件,判断在给定相关文献后,能不能把整理的活干好了
测试时间是2025 年10 月10 日,这个阶段知识库已经可以应对简单的需求,例如客服机器人、规章制度智能检索、文史资料智能检索。然而,任何模型都不能满足理科项目级别的知识库检索,因为理科文献书写时就默认读者有较高的领域知识和科学素养,不同文献间常有实验细节、术语范畴、数值单位的差异,很难被当前的大模型妥善解决
今天测试各模型“对某定义明确的理科问题的信息汇总”能力,我希望结果遵从提示词、遗漏少、无幻觉
参与模型
现在离线私有知识库要么成本高、要么效果差,本文只讨论在线知识库
NotebookLM ,谷歌旗下火出圈的模型,生成播客的功能非常好用,最近也支持生成视频。设计基于知识库,底座模型是定制的 Gemini,不支持选择其他模型
ChatGPT,OpenAI 家喻户晓的产品,目前更新到 GPT-5。ChatGPT 一直以来综合能力领先,逻辑能力、情感模拟、AI 电话很强,代码生成不错,似乎长期记忆也很好(看到很多调教 ChatGPT 的帖子)。ChatGPT 有 project 的概念,在 project 下可以上传文件,然后开启多个会话。虽然有很多模型系列,官方现在已经支持 auto 档,可以自动选择模型
Claude,代码生成这块绝对的王者,综合能力也不弱,目前更新到 Claude Sunnet 4.5。和 ChatGPT 一样有 project 功能
秘塔,王一快搞的 AI 搜索引擎,功能做的很人性化,回答明显比其他 AI 图片更多,追溯引用源的体验很好,是我最常用的 AI 搜索。可以建立知识库,称为“专题”。在提问时,允许限定知识库范围。模型有简洁、深入、深度研究(包含快思考、长思考两种模式)
Kimi,月之暗面的模型,早期因为超长上下文火过一波,我自己用下来的体验一直不算好。不能建立知识库,但每个会话支持最多 50 个文件上传。模型有 K1、K2、深度研究、OK computer,其中“深度研究”不支持上传文件
豆包,字节的模型,很早就出了 AI 电话、提示词市场、声音克隆等功能,是早期AI 电话流畅度最高的模型之一,给人的感觉是更专注浅层需求。不能建立知识库,但每个会话支持最多 50 个文件。模型有普通、深度思考、深入研究
Perplexity,应该是第一个做AI 搜索引擎的。可以建立知识库,称为“Space”。在提问时,可以 @ 特定知识库。免费版单个知识库限制 5 个文件。模型有 search、Research、Labs(需付费)
玻尔,是专为科研人员设计的 AI 搜索模型,内部集成了期刊库、学者库等,还能与 Zotero 联动。可以建立知识库,模型有简洁、专业、思考、深度研究
腾讯 ima,比腾讯元宝的声量小很多,但却是腾讯旗下正经的知识库智能工作平台。网页端不支持创建知识库,必须下载客户端。模型有 DeepSeek V3.1,DeepSeek V3.1 Thinking,Hunyuan 等
另有一些软件使用本地知识库 + api 接入在线模型推理,如 Cherry Studio,本人使用时有一定概率解析文件出错。留待观察
这次测试我给了 8 篇文献,都涉及流感病毒抗体的小鼠攻毒实验,目的是整理出一份信息表

对所有模型使用统一的提示词
梳理文献中提到的所有攻毒实验,同一篇文献有多个攻毒实验的,分开记录
列出抗体名,抗体中和能力,给药方式,给药剂量,小鼠年龄,毒株,病毒剂量,病毒接种时间,抗体给药时间,14d生存率
接下来就纯主观评价各模型的输出吧
Notebook LM
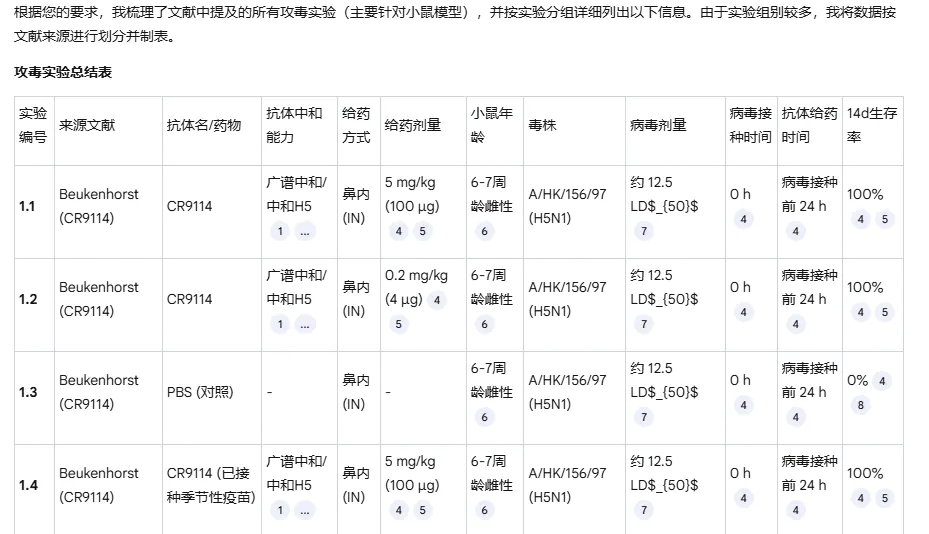
忠实根据提示词,总结 8 篇文献的所有攻毒实验,每个单体、给药剂量单独列出,一共有 80+记录,仅有极少量的实验组被遗漏
ChatGPT
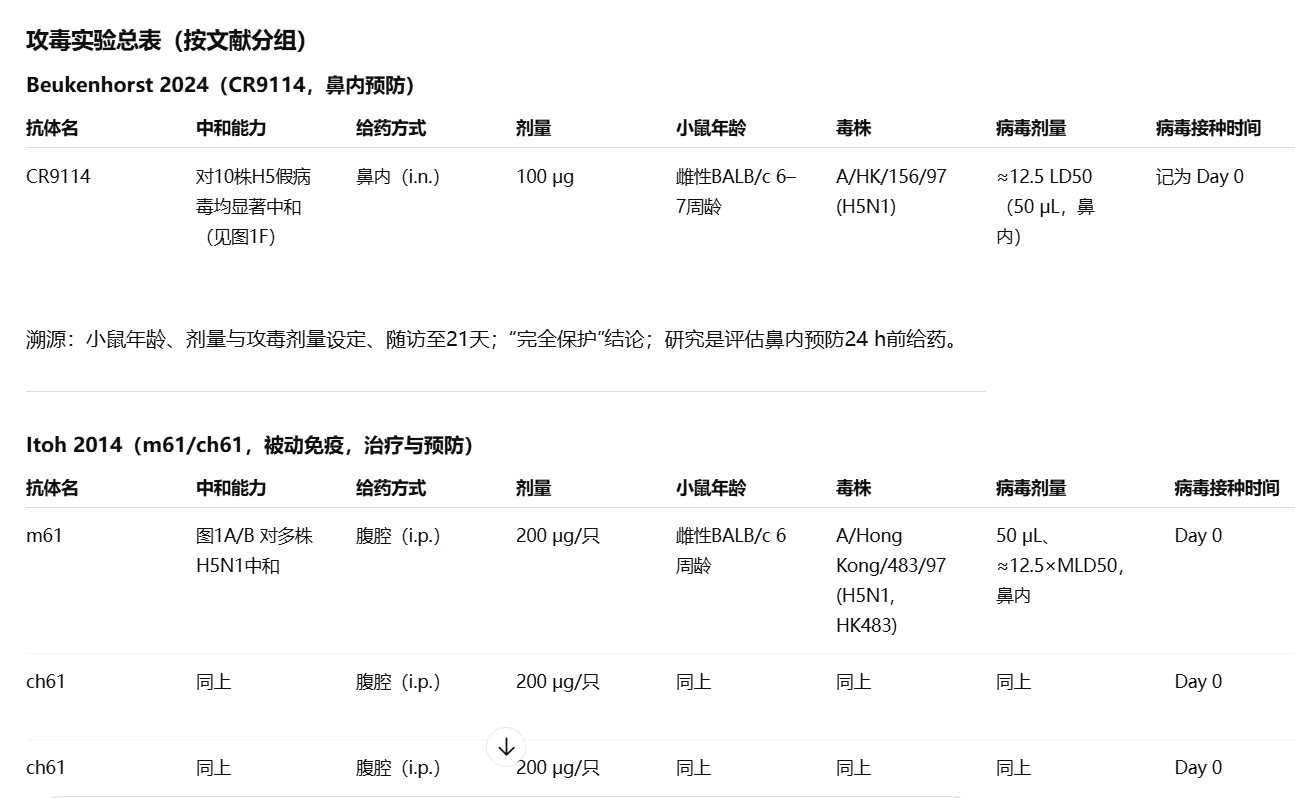
输出遗漏太多,给出的实验组过少。尝试手动指定 Thinking 模式,仍然如此
Claude
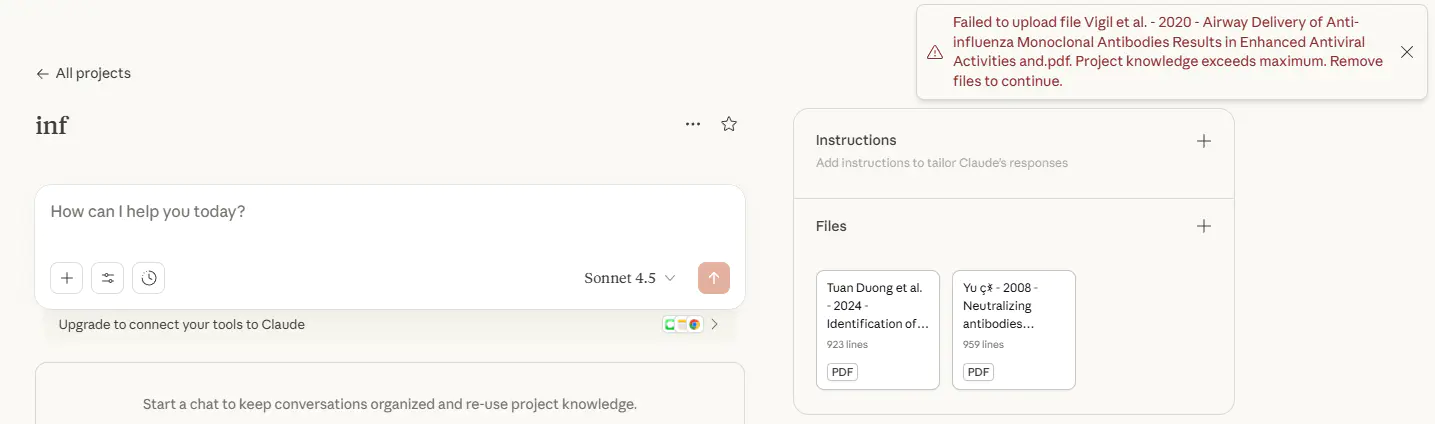
似乎不能上传 2M 以上的文件,直接出局
秘塔
深入

只梳理了 4 篇文献,未按要求把每篇文件中不同攻毒实验分开记录,而是不同毒株、实验组混在一起描述
深度研究(快思考)
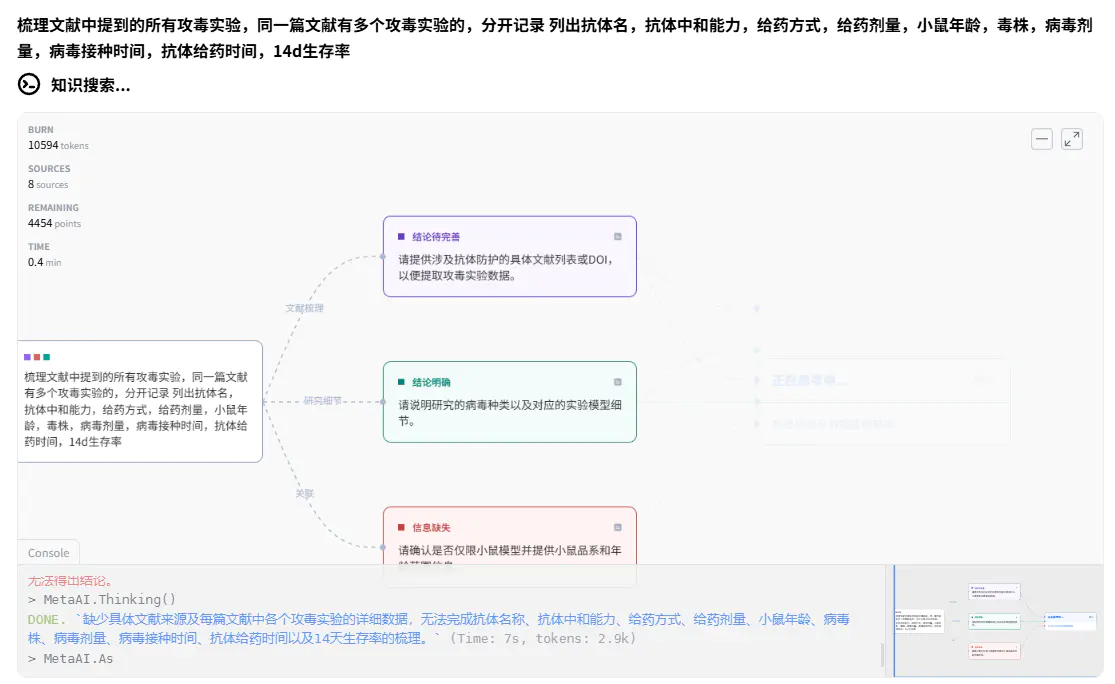
模型思考时,会动态生成思维链,看起来挺炫酷
最终给出的结果,仍然有大量实验缺失。列出的实验中,许多文献有的信息也没找到
另外,在回答中同一个引用源会被重复编号,这可能造成混淆

深度研究(长思考)

相比快思考有改善,但仍有遗漏文献,列出文献中仍有遗漏的信息
perplexity
research

没按照提示词分组,结果非常简陋,信息丢失严重
玻尔
专业
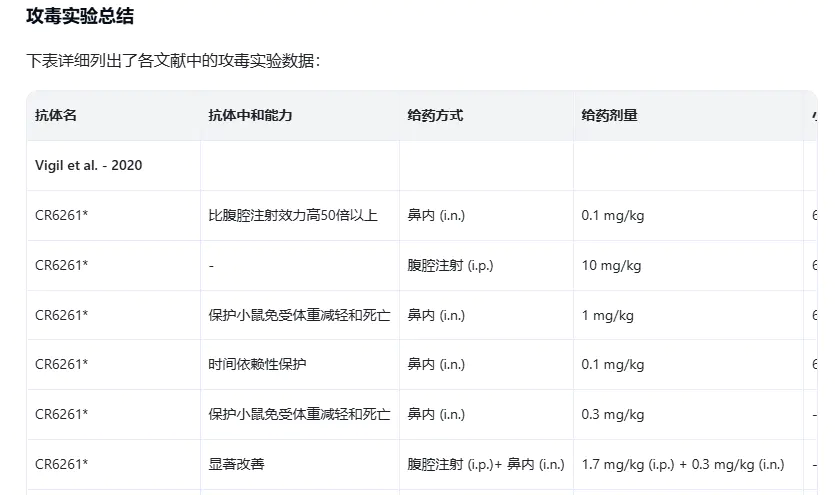
回答中只列出了 3 个文献,对抗体中和能力的理解完全错误
思考

回答中列出了所有文献,36 组记录,考虑到记录有合并的情况,算遗漏较少。每条记录中,遗漏“中和能力”
99.7%、80.2%这些数字,实际应该是 100%、80%,明显通过识别柱状图、计算比例后得到。这是加分项
不太方便的一点是,对话框在浏览器后台标签页时输出会暂停,需要打开多个浏览器窗口解决这个问题
KIMI
K2
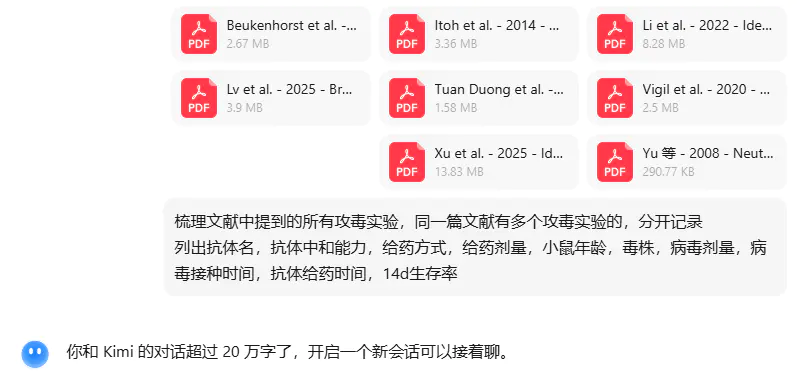
K2 模型无法支持 8 篇文献的上下文
OK computer
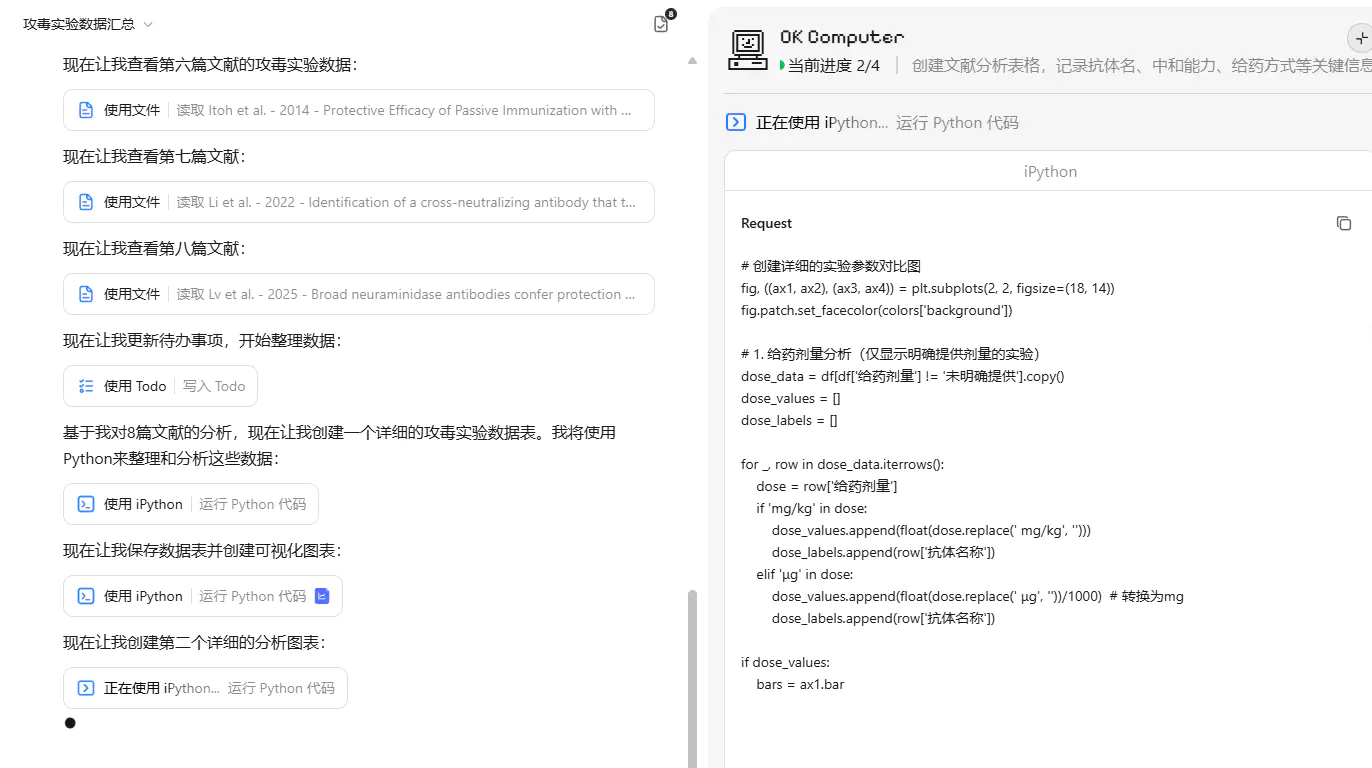
OK computer 是个 agent 的设计,能够调用 todo、ipython 辅助思考和计算
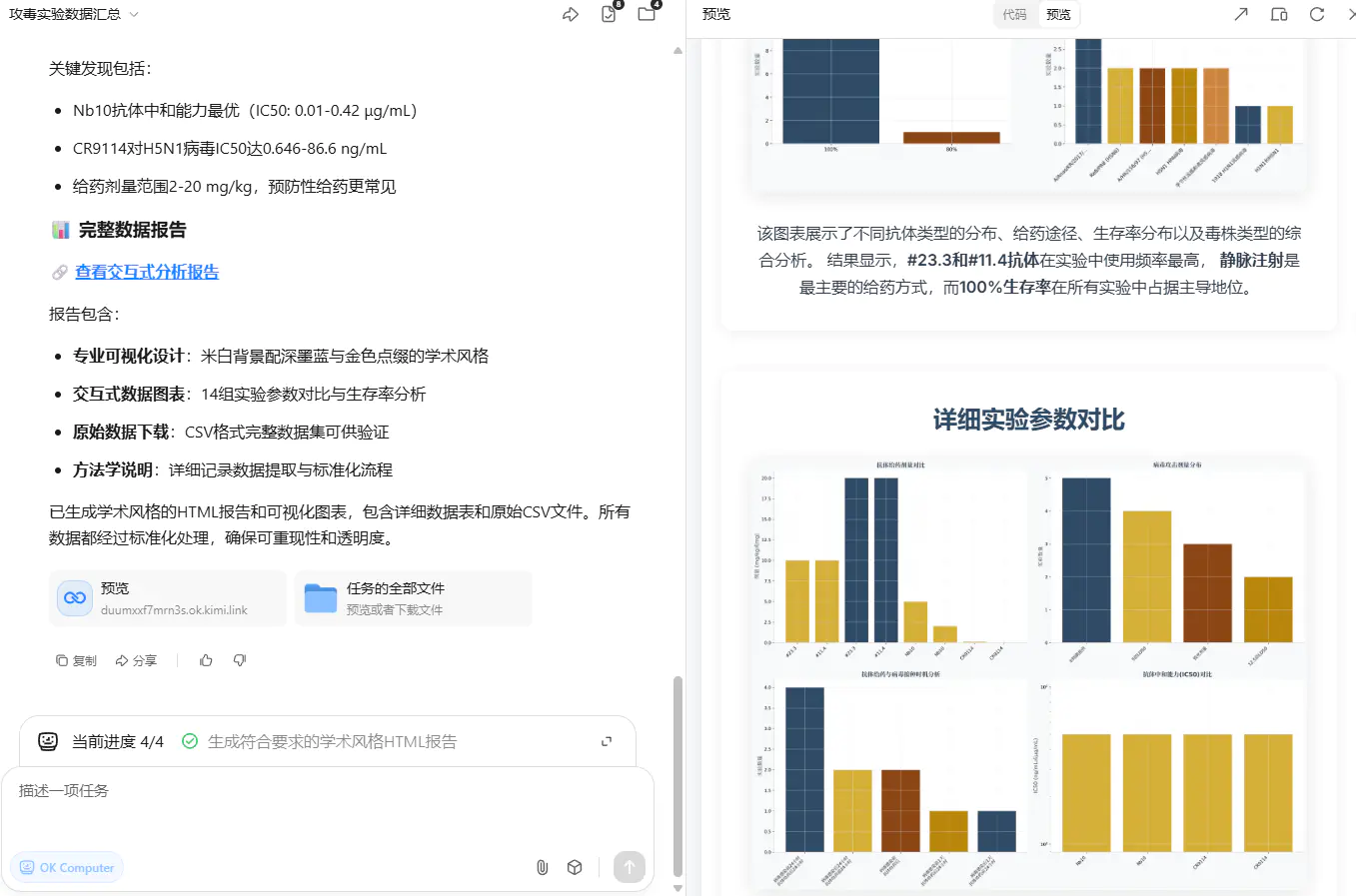
最终生成了交互式网页,但太粗略。导出原始数据后,发现漏了一篇文献,且列出的文献也遗漏很多信息
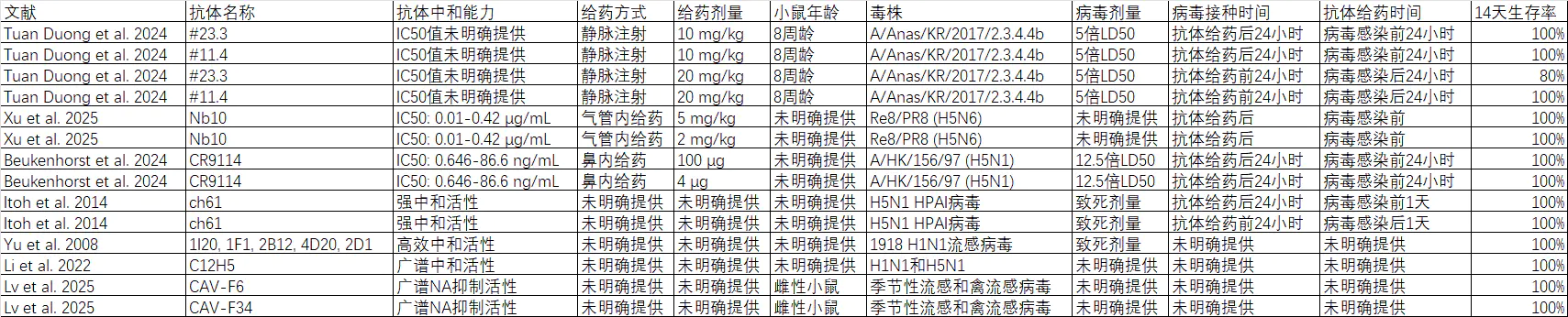
豆包
深度思考

仅提取了 5 篇文献,已列出的文献中有遗漏、错误
腾讯 ima
DeepSeek V3.1
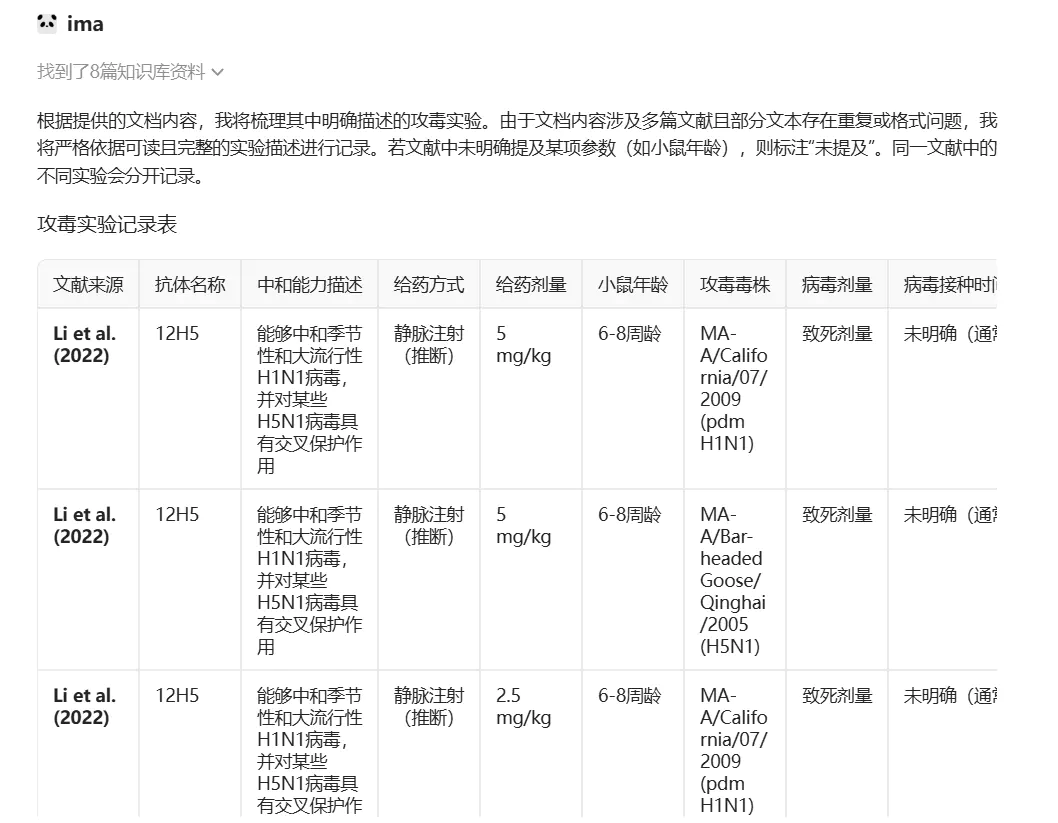
总结了所有 8 篇文献的攻毒实验,但前半部分细致、后半部分粗糙。例如,一开始明确给不同给药剂量分组,但后期就 “2.5mg/kg 及以上”,一开始每个抗体单独列出,后期合并为一行
DeepSeek V3.1 Thinking

恢复为列表格式。总结了大部分实验,内容有遗漏和错误
总结
综合来看,表现最亮眼的是 Notebook LM,其次是玻尔。腾讯 ima 算勉强可用,剩下的都不怎么样,非要排序的话是秘塔 > Kimi > Perplexity > ChatGPT > 豆包 > Claude
这里只测试了直白的提示词,修改提示词后可能结果有变化。也没有测试模型本身作为 api 接入知识库的效果。说白了,这是一个产品体验的测试,而不是模型能力的测试
期待知识库应用能尽快变得便宜、好用